![]()
![]() · · Felix Haase, Ute Schmid · Beitragsreihe KI · 3 min Lesezeit
· · Felix Haase, Ute Schmid · Beitragsreihe KI · 3 min Lesezeit
Wie lernen Computer?
Lernen ist notwendig, damit wir Menschen uns in dieser komplexen Welt zurechtzufinden. Wie ist es möglich, dass Computer etwas ähnliches schaffen können?

Hier können Sie sich den Beitrag in Videoform ansehen.
Im letzten Artikel der Beitragsreihe klaro!KI mit dem Titel “Was ist eigentlich KI?” haben wir uns einen Überblick über KI verschafft. Ausgehend davon wollen wir uns diesmal genauer anschauen, wie Maschinen lernen können.
Maschinelles Lernen
Kleinkinder lernen Katzen und Hunde zu unterscheiden, indem sie von ihren Eltern die richtige Antwort gesagt bekommen. Anfangs wird das Kind noch Fehler machen, und von den Eltern korrigiert. Nach einigen Beispielen wird das Kind die beiden Tiere aber immer besser auseinanderhalten. Bei Maschinellem Lernen funktioniert es ähnlich:
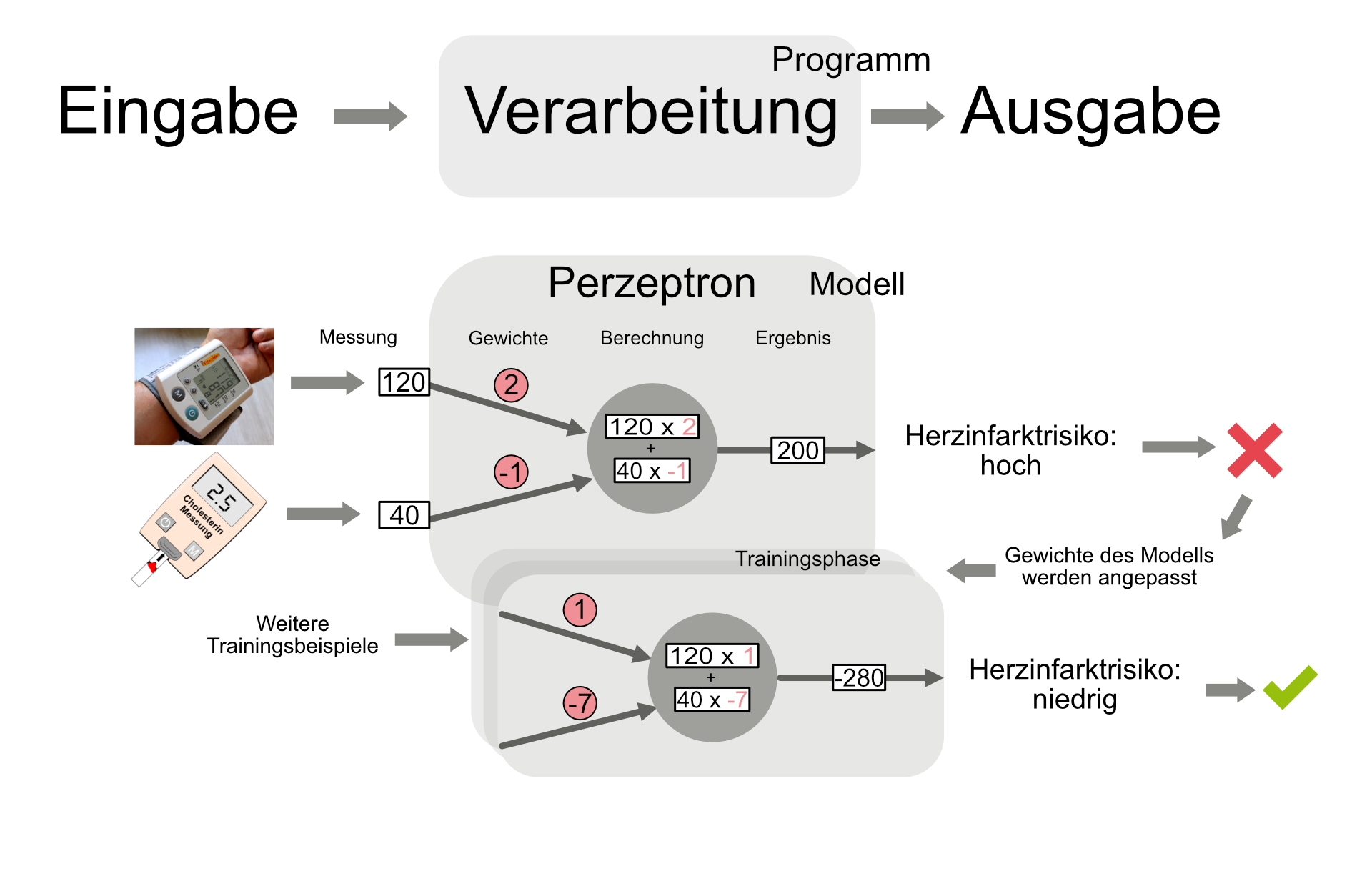
Computer verarbeiten Eingaben mithilfe von Programmen zu Ausgaben. Beim Maschinellen Lernen wird das Programm durch ein aus Daten gelerntes Modell ersetzt. Aufgebaut wird das Modell mit einem Lernalgorithmus, also einem Programm, das Regelmäßigkeiten in Daten erkennt und daraus verallgemeinert. Das Perzeptron ist ein KI-Modell, das vom Neuron im menschlichen Gehirn inspiriert ist. Damit könnte zum Beispiel das Herzinfarktrisiko aus Cholesterin-Spiegel und Blutdruck vorhergesagt werden.
In einer Trainingsphase wird dem Perzeptron eine Liste von Messwerten mit einem bekannten Herzinfarktrisiko gezeigt (sog. Trainingsdaten). Im Perzeptron wird in sogenannten Gewichten gespeichert, wie wichtig die einzelnen Messwerte für die Entscheidung sind. Diese sind anfangs zufällig gesetzt. Die Eingabedaten (je ein Trainingsbeispiel) werden mit den Gewichten verrechnet. Ergibt sich ein Wert größer Null, wird das Herzinfarktrisiko hoch beurteilt, ansonsten als niedrig. Gibt das Perzeptron ein vom Trainingsbeispiel abweichendes Herzinfarktrisiko aus, macht also einen Fehler, werden die Gewichte verändert. Das Perzeptron lernt durch Veränderung der Gewichte, möglichst wenige Fehler zu machen. Das Ziel ist nicht, auswendig zu lernen, sondern zu verallgemeinern, damit das Modell im Einsatz mit echten Daten genauso gut funktioniert.
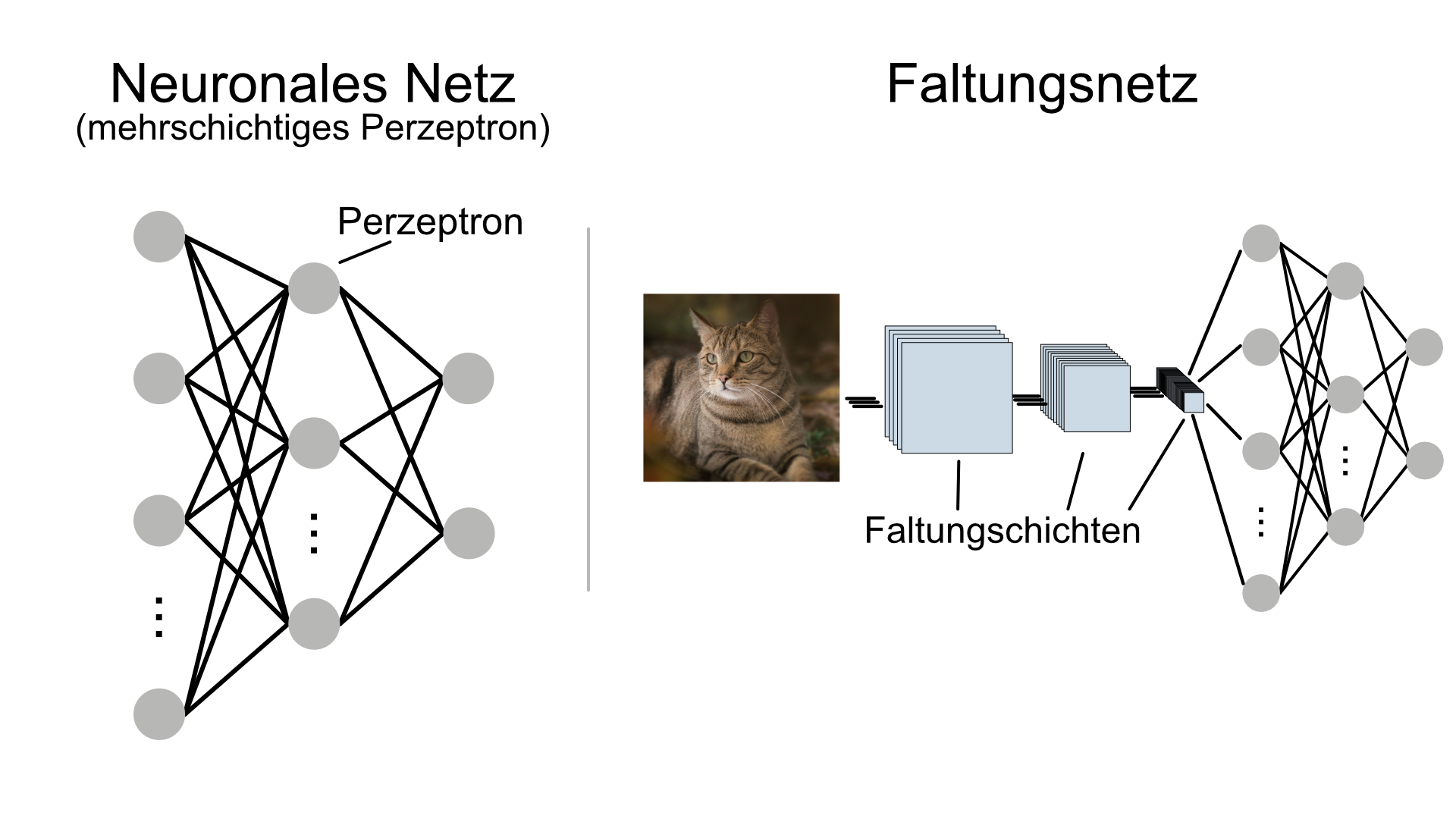
Mit Perzeptronen kann man nur sehr einfache Modelle lernen. Künstliche Neuronale Netze bestehen aus vielen Perzeptronen. Dadurch können komplexe Zusammenhänge gelernt werden. Allerdings sind dafür komplexere Lernalgorithmen notwendig, um die Gewichte sinnvoll zu verändern.
Für Probleme, bei denen Daten nicht als Listen von Messwerten vorliegen, reichen die beschriebenen Neuronalen Netze nicht aus. Will man beispielsweise aus Bildern lernen, Hunde und Katzen zu unterscheiden, müssen die relevanten Informationen erst aus den Bildern ermittelt werden. Hierfür werden sogenannte Faltungsnetzwerke benutzt (Convolutional Neural Networks, CNNs).
Praktische Anwendung
Liefern Modelle für Eingabedaten als Ausgabe eine bestimmte Kategorie (wie Hund oder Katze), spricht man von Klassifikationslernen. Das kann in den verschiedensten Bereichen eingesetzt werden, von der Erkennung von Hautkrebs bis zur Prüfung der Qualität von Schweißnähten.
Für die Umsetzung ist es notwendig, genügend Daten in guter Qualität zu erheben. Geschulte Mitarbeitende müssen dann die Daten annotieren, also in die Kategorien einordnen. Die benötigten Arbeitskräfte für die Annotationen werden auch “Data Worker” genannt. Je nach Komplexität des Problems werden sie günstig im Ausland angeheuert oder brauchen eine Ausbildung in dem Bereich und sind dementsprechend teurer.
Bei manchen Problemen sind sich nicht einmal Experten einig. Das macht es besonders schwer ein KI-Modell zu trainieren.
Was noch fehlt, dass Computer so gut wie Menschen lernen
Durch die Forschung der letzten Jahre können Computer immer besser lernen, und nähern sich dem menschlichen Niveau an. Um KI-Modellen in der Praxis zu vertrauen, fehlt es oft noch an Robustheit und Transparenz. Das heißt, dass die gelernten Modelle im praktischen Einsatz möglichst wenig Fehler machen und dass für Menschen nachvollziehbar ist, wie und warum ein KI-Modell zu der Aussage kommt.
Besonders schwierig ist es bisher für Computer, anhand weniger Beispiele zu lernen. Menschen nutzen beim Lernen immer Dinge, die sie bereits wissen. Im Bereich Maschinelles Lernen, wird versucht, dies nachzubilden, indem die Modelle auf allgemeinen Daten vortrainiert werden.
Einige dieser Hürden kommen daher, dass KI, anders als wir Menschen, nicht wirklich denkt. Das wollen wir im nächsten Beitrag am Beispiel von ChatGPT klären.
Wissen Sie, wie Maschinelles Lernen funktioniert?
Wenn Sie nun ein größeres Interesse an Künstlicher Intelligenz entwickelt haben, können Sie hier kostenlose Weiterbildungs-Möglichkeiten und Demonstratoren finden, die wir für Sie zusammengestellt haben.
Der Beitrag wurde im Kontext des Verbundprojekts klaro!KI der Universität Würzburg und Universität Bamberg vom Bundesministerium für Justiz und Verbraucherschutz gefördert.

Der Beitrag ist unter der Creative Commons Attribution 4.0 Lizenz veröffentlicht. Eingebundene Bilder unterliegen möglicherweise anderen Linzenzen, dies ist in der Bildbeschreibung vermerkt. Teilen, Anpassen und wiederverwerten ist ausdrücklich erwünscht. Folgende Quellenangabe ist dabei zu verwenden:
Felix Haase, Ute Schmid (13. März 2025), Wie lernen Computer? in Beitragsreihe KI, Projekt klaro!KI, https://klaro-ki.de/wie-lernen-computerEmpfohlene Literatur:
- Alpaydin, E. (2022). Maschinelles Lernen. Berlin, Boston: De Gruyter Oldenbourg.
- Otte, Ralf. Künstliche Intelligenz für Dummies. Deutsche Dummies. John Wiley & Sons, 2023.
- Schmid, U., Weitz K. & Siebers M. (2024) Künstliche Intelligenz selber programmieren für Dummies Junior. WILEY VCH
- Russell, S., & Norvig, P. (2023). Künstliche Intelligenz: Ein moderner Ansatz. Pearson.



